How to: Safe and fast rollouts for agent-created code or REST APIs
TL;DR
Agent‑created code or REST APIs move faster than manual development but they also change faster. ratl.ai’s new agentic API testing module turns your OpenAPI file into an executable, conversational test plan: it audits the spec, auto‑builds user‑journey flows across endpoints, runs them, answers questions about the results, and plugs straight into CI/CD. The result is speed with safety for both engineering and product. Below is a step‑by‑step walkthrough using an e‑commerce storefront spec.
Why agent‑created APIs need a different safety net
Engineering and product teams are increasingly using code‑gen and agents to design endpoints, scaffolding, and even the first set of tests. That speed is a gift and a liability.
Common failure modes:
- Contract drift between versions (types, enums, response codes) that unit tests miss.
- Hidden couplings (e.g.,
create → get → patch → listflows) that break under real traffic. - Auth & pre‑req gaps (tokens, seed data, ordering) that make tests pass locally but fail in staging.
- Change blast radius that product can’t easily quantify ahead of a release.
Traditional endpoint‑by‑endpoint testing doesn’t catch these. You need flow‑aware, spec‑aware, and change‑aware validation—ideally generated at the same speed your agents create APIs.
Meet ratl.ai’s agentic API testing
ratl.ai’s new module takes natural‑language inputs and your OpenAPI as the source of truth, then builds and executes end‑to‑end validation for you. Highlights:
- Reads OpenAPI specs and understands diffs across versions.
- Audits your spec for contract health and consistency.
- Generates scenarios and correlations between APIs (multi‑step “user‑journey” flows).
- Builds API execution flow graphs (you can edit the flow in natural language).
- Lets you add pre‑req scripts, tokens/secrets, headers, fixtures.
- Persists execution runs for deterministic re‑runs and CI/CD integration.
- Performs impact analysis when a particular API changes—showing affected flows.
- All inside a ChatGPT‑style UI that’s intentionally friendly to both engineers and PMs.
What you’ll see in this walkthrough
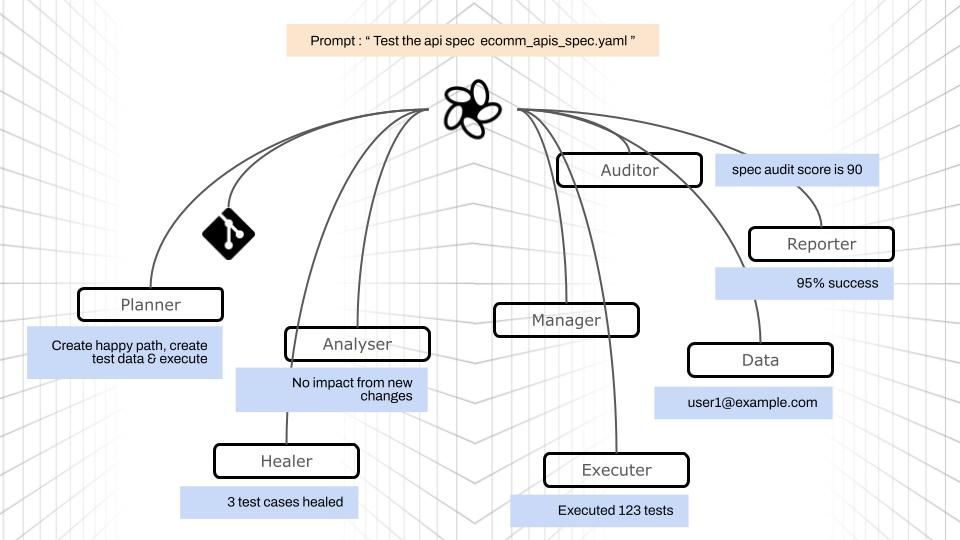
We’ll use a e‑commerce storefront OpenAPI spec and show the flow from first prompt → audit → happy‑path generation → execution → reporting → CI/CD.
- Kickoff prompt
test the apis in the spec https://dev.azure.com/****/sample-ecomm-apis?path=/openapi_spec.yaml in main branch - Spec audit with actionable recommendations
- Auto‑generated happy‑path graph across endpoints
- Execution (including interactive fixes like “use a unique dummy email”)
- Report & Q&A (e.g., “What’s the average response time?”)
- Integration with Jenkins (or any CI)
The sample spec defines endpoints such as/auth/register,/auth/login,/products,/cart/items,/checkout, and/orders, with JWT BearerAuth protecting cart/checkout/order paths. Request bodies and examples are present, which ratl uses to stitch flows and derive data dependencies.
1) Start with one prompt
Paste a link to your spec (Git, DevOps, S3—anywhere your file lives) and say what you want in plain English:
test the apis in the spec https://dev.azure.com/****/sample-ecomm-apis?path=/openapi_spec.yaml in main branch
ratl’s retrieval agent fetches the file, validates it, and hands it to the audit agent.
2) Spec audit: fast, explainable guardrails
ratl reads the spec and produces an audit with a readiness score and AI recommendations—think contract hygiene, examples, tagging, and consistency checks.
Typical guidance includes: add operationIds, use tags to group endpoints (Products, Auth, Orders), expand examples (especially edge cases), and split shared schemas. You can accept suggestions or proceed if the score meets your policy.
3) Auto‑generate a happy‑path flow (and edit it with plain English)
Once the audit clears, the orchestrator agent and test_generation agent build an end‑to‑end user journey from registration → login → browse → (add to cart) → checkout. All of this is inferred directly from your spec: security requirements, request bodies, and example payloads.
The canvas is editable with NLP. Example tweaks:
- “After login, add a step to list products in the books category.”
- “Insert a negative case for
/cart/itemswith an invalid token.” - “Run cart reads in parallel; cap concurrency at 3.”
Behind the scenes, ratl automatically:
- Stitches dependencies (e.g., uses the token from
/auth/loginfor all protected endpoints). - Populates request bodies from examples or prior responses (e.g., product ids from
/productsfor/cart/items). - Sets pre‑reqs (tokens, seeded data) and masks secrets.
4) Execute and fix issues conversationally
The test_execution agent steps through the graph with real requests against your environment.
In our sample run, registration returned 409 (Conflict) because the example email from the spec was already taken:
No need to edit JSON by hand. Just say:
“Use a unique dummy email ID.”
The agent regenerates the input (e.g., user_test_1717593830@example.com) and resumes the flow.
4.1) New: Fix flow variables live (token example)
Sometimes failures come from stale or misplaced variables. Because the spec protects /cart, /cart/items, /checkout, and /orders with BearerAuth, the run will fail (403) if a wrong token is used.
Here’s exactly how a user corrects it in conversation:
You: “show the token received from login”
ratl: returns the JWT captured from the latest successful/auth/login.
You: “see the token in /items is wrong. fix this”
ratl: acknowledges, updates the flow’s variable bindings to use the latest valid login token across all secured steps, and offers to re‑run.
Confirm, and the system re‑executes with the corrected token:
What changed under the hood
- Flow‑level variable is re‑bound to the most recent
login.access_token. - All nodes with
security: BearerAuthare re‑parameterized to use that token. - Retrying logic is applied if a token expires mid‑flow (401/403).
5) Reports you can interrogate
After execution, ratl produces a Test Execution Report—coverage, pass/fail/skipped, minimal repro details, and performance snapshots.
In this example:
- Total endpoints tested: 10
- Passed: 3 • Failed: 1 • Skipped: 6
- The failure on
POST /ecommerce/cart/itemswas a 403 due to an invalid/expired token—useful for tightening token lifetimes and re‑auth logic in the flow.
And because everything is conversational, you can ask:
“What’s the avg response time?”
Answer: ~0.258s for the last run. You can keep asking: “Which endpoint regressed vs last green run?”, “Show only 4xx errors,” “Export as JUnit.”
6) Rerun, edit, or wire it into CI/CD
From here you can iterate on the canvas, persist the run for deterministic re‑runs, or turn it into a release gate.
Why this works (and what’s actually “agentic”)
Under the hood ratl uses a LangGraph orchestration of specialized agents—audit, retrieval, orchestrator, test_generation, impact_analysis, test_execution, bug_reporter, and test_reporting—all powered by OpenAI. This makes the system both:
- Spec‑aware (reads your OpenAPI and diffs versions),
- Flow‑aware (reasons across endpoints and data dependencies), and
- Change‑aware (impact analysis when a single endpoint changes)
What engineering & product each get
Engineering
- Contract drift detection with actionable diffs.
- End‑to‑end flows that automatically reuse tokens and IDs from prior steps.
- Minimal repros and traces tied to each failure.
- Deterministic re‑runs and easy CI gates.
Product
- A canvas that mirrors real user journeys (registration → login → browse → cart → checkout).
- Plain‑English policies turned into automated release gates.
- Conversational reporting (ask “What changed since v1.0?” or “Show all flows touching checkout”)
Pro tips & guardrails
- Keep the spec the source of truth. Add examples and tags; they improve test quality and agent reasoning.
- Model real journeys, not just endpoints. Ensure at least one multi‑step flow for each critical path (e.g.,
register → login → products → cart/items → checkout). - Use natural‑language edits. Ask for negative tests, concurrency caps, or alternate branches—no brittle test code.
- Persist “green” baselines. Gate releases on perf drift (e.g., P95 +15%), error budgets, and backward‑compatibility checks.
- Close the loop. When the agent pauses (e.g., duplicate email), fix it conversationally (“use a unique dummy email”) and resume.
Capabilities snapshot (all from NLP)
- Read OpenAPI specs; understand and audit changes.
- Generate scenarios and correlations across APIs; build execution flow graphs.
- Edit flows via natural language; add pre‑req scripts, tokens, and fixtures.
- Persist runs for re‑runs and CI/CD integration.
- Impact analysis when any API changes.
- A ChatGPT‑style UI designed for both engineers and PMs.
Try it on your spec
- Paste your spec link and say:
test the apis in the spec <your-url> in main branch - Review the audit.
- Approve the happy‑path (or edit it conversationally).
- Run, ask questions, and wire it into CI.
Fast rollouts don’t have to be risky—and safe rollouts don’t have to be slow. With ratl.ai’s agentic testing, your OpenAPI file becomes a living, conversational safety net for every release.